Underlying dimensions of semantic change
[ENGLISH TRANSLATION BY GEMINI BELOW]
Được một hôm tương đối rảnh rỗi nên chia sẻ nhanh về chủ đề mình đang làm.
Chúng ta đều biết rằng ngôn ngữ, đặc biệt là ngữ nghĩa của từ luôn có sự thay đổi, vậy làm thế nào để ta nhận ra sự thay đổi đó?
Cách đơn giản nhất là ta tra từ điểm ở các thời điểm ta muốn so sánh, tuy nhiên cách này không uy tín cho lắm vì mỗi từ điển có thể định nghĩa 1 kiểu khác nhau, chưa kể cách hiểu của mọi người cũng có thể khác so với cách mà từ điển định nghĩa. Và không phải thời đại nào cũng có từ điển để tra cứu.
Một cách nữa là đi hỏi những người ở các thế hệ khác nhau và so sánh cách hiểu của họ về một (số) từ nào đó. Tuy nhiên đôi khi sự khác nhau giữa các cách hiểu mang tính cá nhân chứ không phải mang tính thế hệ, tức 2 người ở cùng 1 thế hệ cũng có thể hiểu khác nhau. Để khắc phục vấn đề này, ta có thể hỏi nhiều người hơn. Tuy nhiên làm như vậy cũng rất mất công vì ta phải đảm bảo rằng các yếu tố khác như vùng miền, trình độ học vấn, vv là tương đối giống nhau. Và ta cũng không thể tìm ra được sự thay đổi cách quá 100 năm (tức 1 đời người) và kể cả nếu ta có muốn rút ngắn lại thì chưa chắc những người ở thế hệ trước đã còn để mà hỏi.
Thật may mắn là chúng ta lưu giữ rất nhiều các tài liệu, văn bản từ hang trăm năm trước. Và với thời đại 4.0 hiện nay thì việc thu thập dữ liệu của ngôn ngữ hiện đại dễ hơn bao giờ hết. Nếu ta tạm giả sử ngôn ngữ được sử dụng trong những tài liệu này đại diện cho ngôn ngữ chung của thời điểm chúng được viết ra (tất nhiên còn nhiều yếu tố khác nữa nhưng ta không bàn đến ở đây) thì ta có thể dễ dàng so sánh được bằng cách so sánh 2 khối ngữ liệu này.
Vậy là ta đã xong phàn dữ liệu, tiếp đến là phần phân tích.
Làm thế nào để ta xác định nghĩa của một từ mà không dựa vào từ điển (vì những lí do ở trên)? Theo distributional semantics, ta có thể hiểu nghĩa của một từ dựa vào những từ đi kèm với nó. Ví dụ, thay vì việc phải dùng định nghĩa như: ‘Bách: Một người đẹp trai thông minh’ thì ta có thể xem Bách thường xuất hiện trong những ngữ cảnh nào. Ví dụ:
Hôm qua em gặp anh Bách ở trên LAB, thấy anh ý NGẦU lắm. (2024) Bách mới DEBUG xong một đống CODE. (2024) Và người nhận GIẢI LUẬN VĂN XUẤT SẮC NHẤT … là Bách. (2022) Thông qua việc phân tích như thế này, ta có thể dễ dàng so sánh ngữ cảnh của 1 từ ở 2 thời điểm khác nhau để tìm thấy sự thay đổi về ngữ nghĩa. Nếu như mình cho các bạn thêm 3 ví dụ từ 2017 thì các bạn có thấy sự thay đổi nào không?
Thằng Bách lại BÙNG HỌC ĐI TẬP RỒI. (2017) Hôm qua thấy Bách SQUAT 190kg không đai chất vcl. (2017) Tí thì bị Bách TAKE DOWN, may mà PULL GUARD kịp. (2017) Nếu bạn có thể thấy và hiểu được sự thay đổi thì xin chúc mừng, bạn đủ điều kiện để trờ thành 1 nghiên cứu sinh trong dự án của mình.
Tuy nhiên đời không như mơ, và không phải lúc nào 1 luận án Tiến Sĩ cũng dễ ăn như vậy. Đôi khi chúng ta sẽ thu thập được 1 đống các ngữ cảnh khác nhau và không thể suy ra được sự thay đổi một cách rõ ràng. Ví dụ, nếu như ta coi ngữ cảnh ở đây là những người mà Bách chơi cùng.
Hùng, Linh, Mạnh (2017) Thắng, Dũng, Quân (2022) Có thể thấy rằng đã có sự thay đổi, nhưng cụ thể là thay đổi như thế nào? Tại sao? Lúc này, ta phải phân tích tiếp ngữ cảnh đó, để tìm ra chiều ẩn (underlying dimensions). Nếu như ta phân tích bài hát mà họ thích, ta có:
Hùng: EDM, Pop, Rap Linh: Jack 5 củ, Sếp Mạnh: Rock, Rap Thắng: Opera, Pop Dũng: Tiền chiến, Cách mạng Quân: Opera, Rock Từ phân tích trên, ta có thể đưa ra giả thuyết rằng Bách đã thay đổi và có sự thay đổi này vì gu âm nhạc của Bách đã thay đổi. Tuy nhiên đây chỉ là một chiều, nếu ta phân tích theo môn thể thao, món ăn ưa thích, vv thì có thể suy ra nhiều thứ khác nữa.
Trên lí thuyết, ta có thể đi sâu hơn nữa với các chiều ẩn (trong trường hợp này là ngữ cảnh của ngữ cảnh, hay n-th order context words). Tuy nhiên ta sẽ gặp 1 số vấn đề.
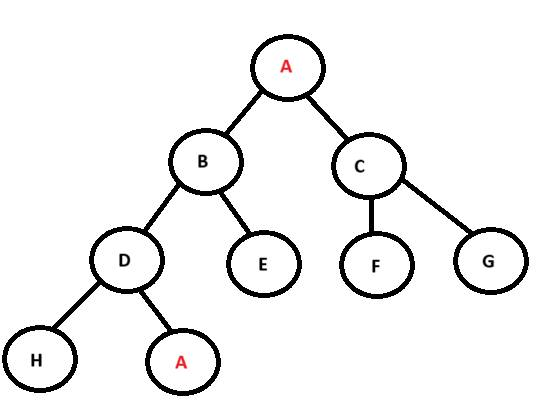
Càng đi sâu vào chiều ẩn thì sẽ càng khó giải thích. Lượng từ vựng trong ngôn ngữ là có hạn, đến một chiều ẩn nào đó thì tất cả từ vựng sẽ liên kết với nhau và việc phân tích trở nên vô nghĩa (xem ảnh).
ENGLISH TRANSLATION
We all know that language, especially the meanings of words, are constantly changing. So how can we recognize these changes?
The simplest way is to look up words in dictionaries from different time periods. However, this isn’t very reliable because different dictionaries might have different definitions, and people’s understanding can also be different from the dictionary’s definition. Plus, not every era had dictionaries to consult.
Another way is to ask people from different generations and compare their understanding of a particular word(s). But sometimes, the differences in understanding are personal rather than generational, meaning two people from the same generation might have different interpretations. To overcome this, we can ask more people. However, doing so is also very time-consuming because we need to ensure that other factors like region, education level, etc., are relatively similar. And we can’t find out changes that occurred more than 100 years ago (or a lifetime), and even if we wanted to shorten that time frame, we can’t be sure if people from the previous generation are still alive.
Fortunately, we have preserved a lot of documents and texts from hundreds of years ago. And in this technological era, collecting data on modern language is easier than ever. If we assume that the language used in these documents represents the common language of the time they were written (of course, there are many other things to be considered, but we won’t discuss them here), then we can easily compare them by comparing these two data sets.
So, we’ve finished the data part; next is the analysis part.
How can we determine the meaning of a word without relying on a dictionary (for the reasons mentioned above)? According to distributional semantics, we shall know a word by the company it keeps. For example, instead of using a definition like: ‘Bách: A handsome and intelligent person,’ we can see in what contexts Bách usually appears. For example:
Yesterday I met Bách at the LAB, he looked so COOL. (2024) Bách just finished DEBUGGING a bunch of CODE. (2024) And the winner of the OUTSTANDING THESIS AWARD… is Bách. (2022) Through analysis like this, we can easily compare the context of a word at two different time points to find changes in meaning. If I give you three more examples from 2017, can you see any changes? Bách is STUDYING HARD AGAIN. (2017) Yesterday I saw Bách SQUAT 190kg without a belt, damn. (2017) I was almost TAKEN DOWN by Bách, luckily I pulled GUARD in time. (2017) If you can see and understand the change, congratulations, you are qualified to become a research student in my project. However, not every doctoral dissertation is that easy. Sometimes we will collect a bunch of different contexts and cannot clearly infer the change. For example, if we consider the context here as the people Bách hangs out with:
Hùng, Linh, Mạnh (2017) Thắng, Dũng, Quân (2022) It can be seen that there has been a change, but specifically what kind of change? Why? At this point, we need to further analyze that context to find the underlying dimensions. If we analyze the songs they like, we have: Hùng: EDM, Pop, Rap Linh: Jack 5 củ, Sếp Mạnh: Rock, Rap Thắng: Opera, Pop Dũng: Pre-war, Revolution Quân: Opera, Rock From the above analysis, we can hypothesize that Bách has changed and that this change is because Bách’s musical taste has changed. However, this is just one dimension, if we analyze according to sports, favorite food, etc., we can infer many other things. In theory, we can go deeper into the underlying dimensions (in this case, the context of the context, or n-th order context words). However, we will encounter some problems.
The deeper we go into the underlying dimensions, the harder it is to explain. The vocabulary in a language is limited, at some underlying dimension, all vocabulary will be linked together and analysis becomes meaningless (see image).